docker ps
Table of Contents
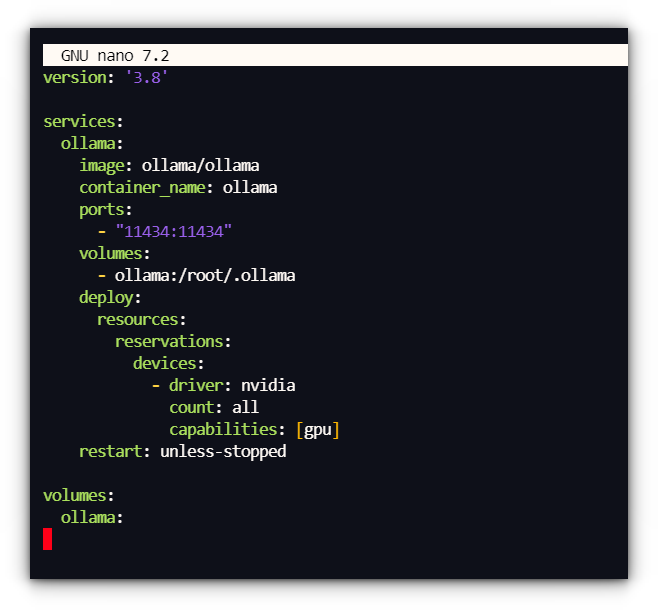
Method 2: Running Ollama with Docker compose
Ollama exposes an API on http://localhost:11434, allowing other tools to connect and interact with it. That was when I got hooked on the idea of setting up Ollama inside Docker and leveraging GPU acceleration.docker exec -it ollama <commands>
I’m considering testing it with Jellyfin for hardware-accelerated transcoding, which would be a huge boost for my media server setup. Now, to install the NVIDIA Container Toolkit, follow these steps:
- Using a one liner
docker runcommand. - With Docker compose
Ollama has been a game-changer for running large language models (LLMs) locally, and I’ve covered quite a few tutorials on setting it up on different devices, including my Raspberry Pi.
We’ll start with creating a docker-compose.yml file, to manage the Ollama container:That said, I’d love to hear about your setup! Are you running Ollama in Docker, or do you prefer a native install? Have you tried any Web UI clients, or are you sticking with the command line? docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
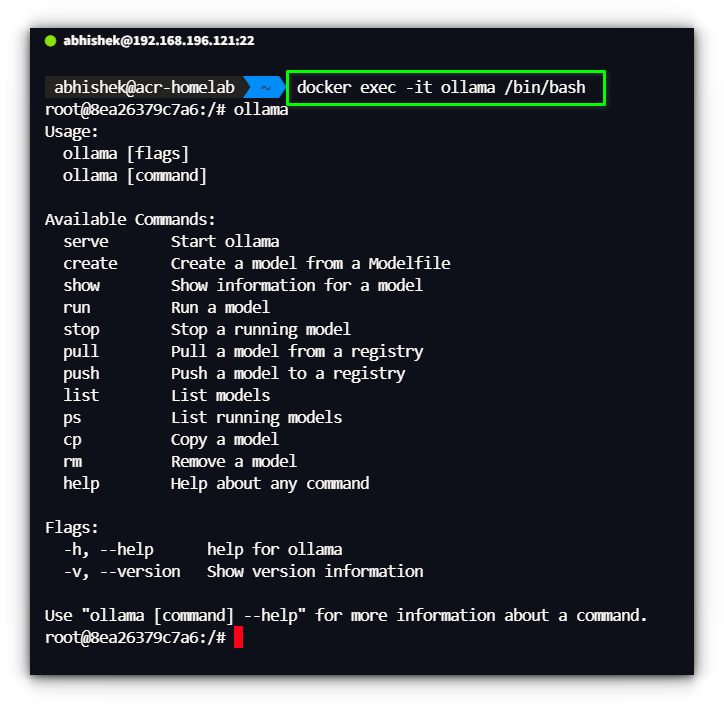
But as I kept experimenting, I realized there was still another fantastic way to run Ollama: inside a Docker container.We’ve actually covered 12 different tools that provide a Web UI for Ollama. This is really easy, you can access Ollama container shell by typing:
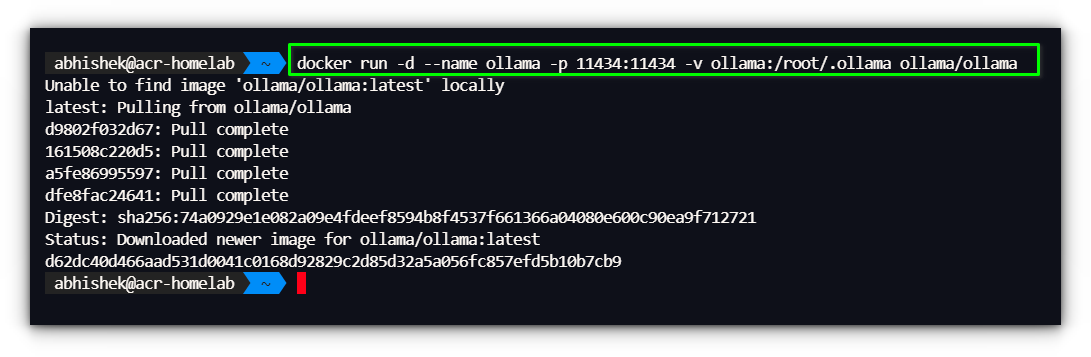
docker run -d: Runs the container in detached mode.--name ollama: Names the container “ollama.”-p 11434:11434: Maps port 11434 from the container to the host.-v ollama:/root/.ollama: Creates a persistent volume for storing models.ollama/ollama: Uses the official Ollama Docker image.
In this guide, I’ll walk you through two ways to run Ollama in Docker with GPU support:On another note, diving deeper into NVIDIA Container Toolkit has sparked some interesting ideas. The ability to pass GPU acceleration to Docker containers opens up possibilities beyond just Ollama.
echo 'alias ollama="docker exec -it ollama ollama"' >> $HOME/.bashrc
source $HOME/.bashrc
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt update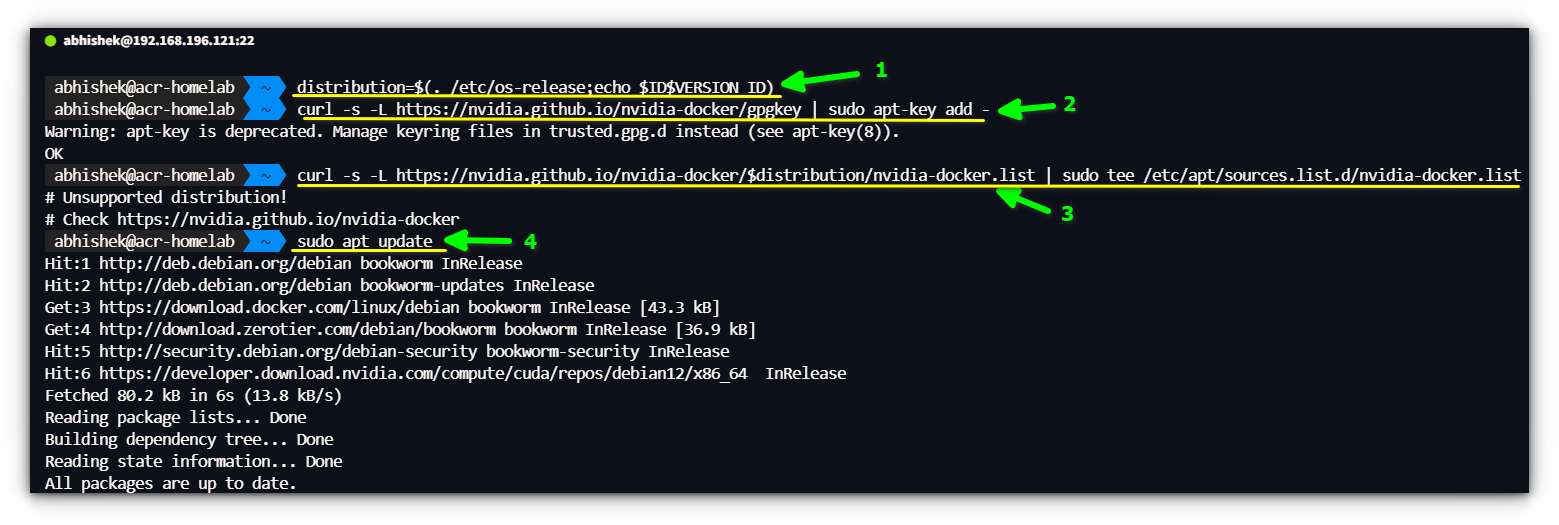
- Install the NVIDIA Container Toolkit by running the following command in a terminal window:
Running Ollama in Docker provides a flexible and efficient way to interact with local AI models, especially when combined with a UI for easy access over a network.Once the container is running, you can check its status with:
Accessing Ollama in Docker
docker run -d --name ollama -p 11434:11434 -v ollama:/root/.ollama ollama/ollama
It wasn’t until I was working on an Immich tutorial that I stumbled upon NVIDIA Container Toolkit, which allows you to add GPU support to Docker containers.
1. Using the Docker shell
Before installation, make sure that you have already installed the GPU drivers on your specific distro.Add this to your .bashrc file:Other projects, like Stable Diffusion or AI-powered upscaling, could also benefit from proper GPU passthrough.There are two main ways:I’m still tweaking my setup to ensure smooth performance across multiple devices, but so far, it’s working well.💡
2. Using Ollama’s API with Web UI Clients
docker-compose up -d

Now, this isn’t exactly breaking news. The first Ollama Docker image was released back in 2023. But until recently, I always used it with a native install. Drop your thoughts in the comments below.
- Open WebUI – A simple and beautiful frontend for local LLMs.
- LibreChat – A powerful ChatGPT-like interface supporting multiple backends.
📋Now, let’s dive in.
Conclusion
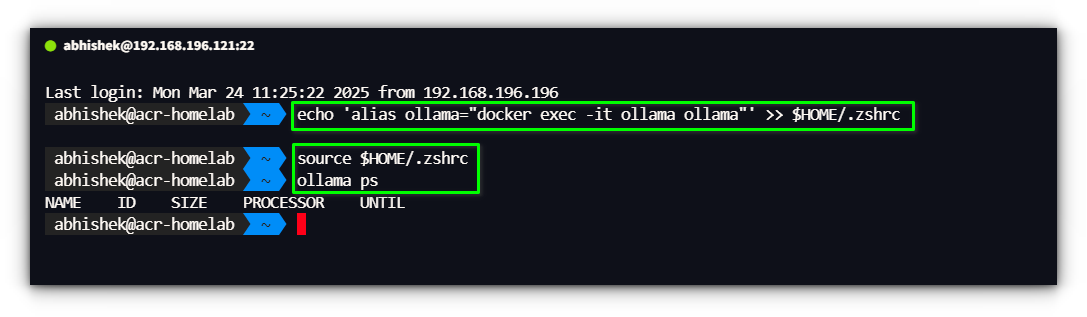
The NVIDIA Container Toolkit includes the NVIDIA Container Runtime and the NVIDIA Container Toolkit plugin for Docker, which enable GPU support inside Docker containers.echo 'alias ollama="docker exec -it ollama ollama"' >> $HOME/.zshrc
Now that we have Ollama running inside a Docker container, how do we interact with it efficiently? If you’re setting up Ollama with Open WebUI, I would suggest to use docker volumes instead of bind mounts for a less frustrating experience. ollama ps
ollama pull llama3
ollama run llama3
version: '3.8'
services:
ollama:
image: ollama/ollama
container_name: ollama
ports:
- "11434:11434"
volumes:
- ollama:/root/.ollama
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
restart: unless-stopped
volumes:
ollama:
Some popular tools that work with Ollama include: