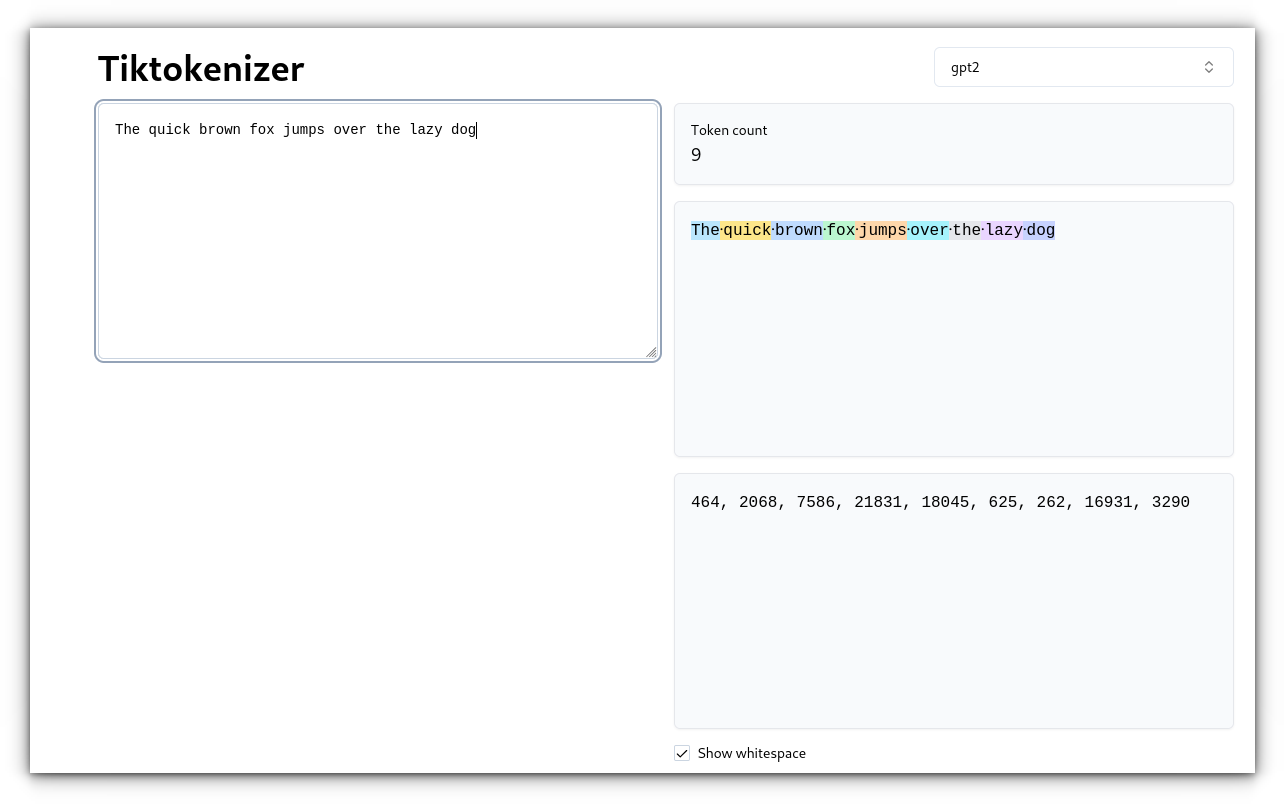
It can be as short as a single letter or as long as a word or even part of a word. Think of it as the unit of language that an AI model uses to process information. Instead of reading entire sentences in one go, it breaks them down into these little digestible pieces – tokens.Example: Original text: “cat” Tokens: [“c”, “a”, “t”]For example, the sentence “The quick brown fox jumps over the lazy dog” could be tokenized as follows:This means that everything in the interaction, from the prompt you send to the model’s response, must fit within that limit.
Table of Contents
What are tokens?
2. Subword-Level TokenizationThis method splits text into individual characters. This is the simplest approach where the text is split by spaces and punctuation. Each word becomes its own token.
In simpler words:
For example, “running” and “runner” are treated as separate tokens even though they share a root. I’d love to hear your thoughts – drop a comment below and let me know how you think advancements in tokenization could affect language models’ ability to handle complex or multilingual text!
In fact, tokens are at the core of how LLMs process and generate text. If you’ve ever wondered why an AI seems to stumble over certain words or phrases, tokenization is often the culprit.
How do language models use tokens?
A token limit refers to the maximum number of tokens an LLM can process in a single input, including both the input text and the generated output.
- Understand the meaning: The model can recognize patterns and relationships between tokens, helping it understand the overall meaning of a text.
- Generate text: By analyzing the tokens and their relationships, the model can generate new text, such as completing a sentence, writing a paragraph, or even composing an entire article.
Tokenization Methods
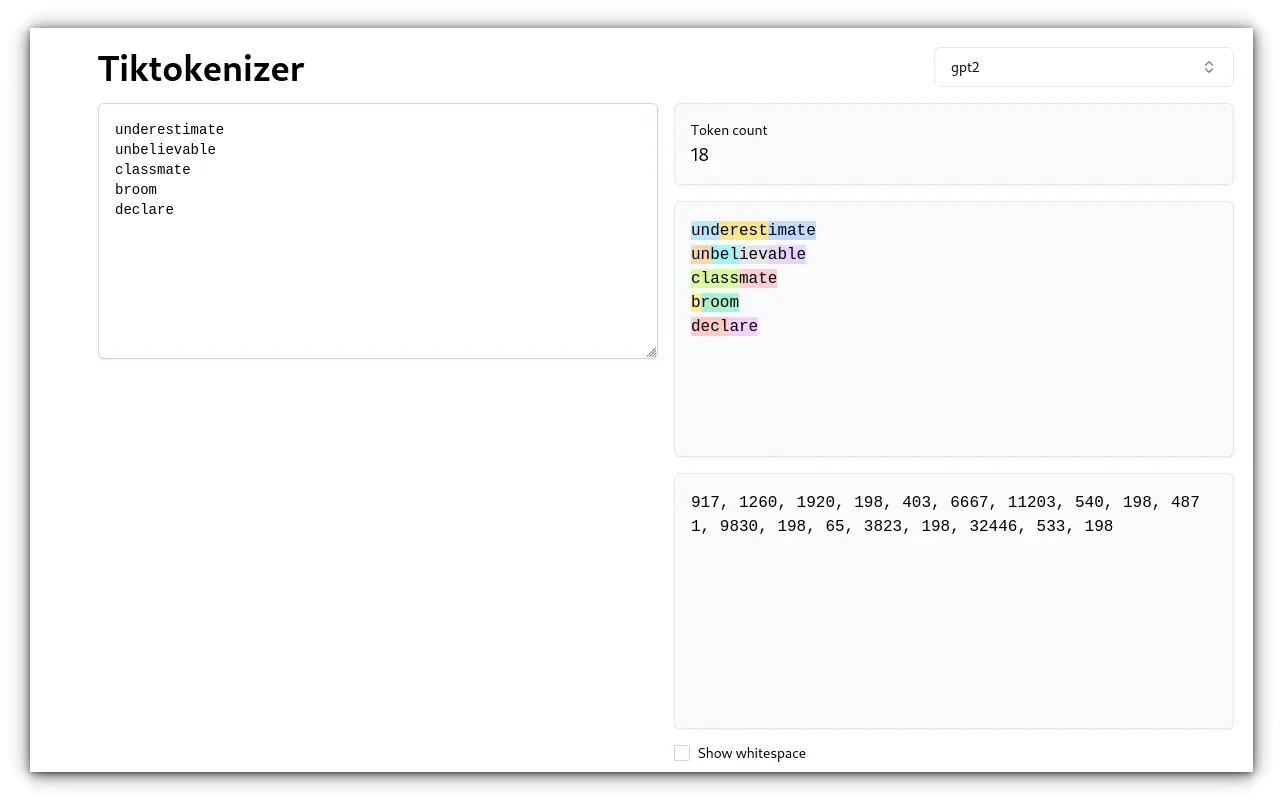
Two popular algorithms are Byte Pair Encoding (BPE) and WordPiece.Example (with BPE): Original text: “underestimate” Tokens: [“und”,”erest”, “imate”] and few others:While this is straightforward, it can be inefficient. Tokens are essential for understanding how LLMs function.If you’ve been following our articles on Large Language Models (LLMs) or digging into AI, you’ve probably come across the term token more than a few times. But what exactly is a “token,” and why does everyone keep talking about it? 3. Character-Level Tokenization
💡For example, GPT-3 can handle up to 4096 tokens, while GPT-4 can process up to 8192 or even 32,768 tokens, depending on the version. It’s very flexible and can handle any text, including non-standard or misspelled words. Byte-level tokenization splits text into bytes rather than characters or words. However, it can be less efficient for longer texts because the model deals with many more tokens.
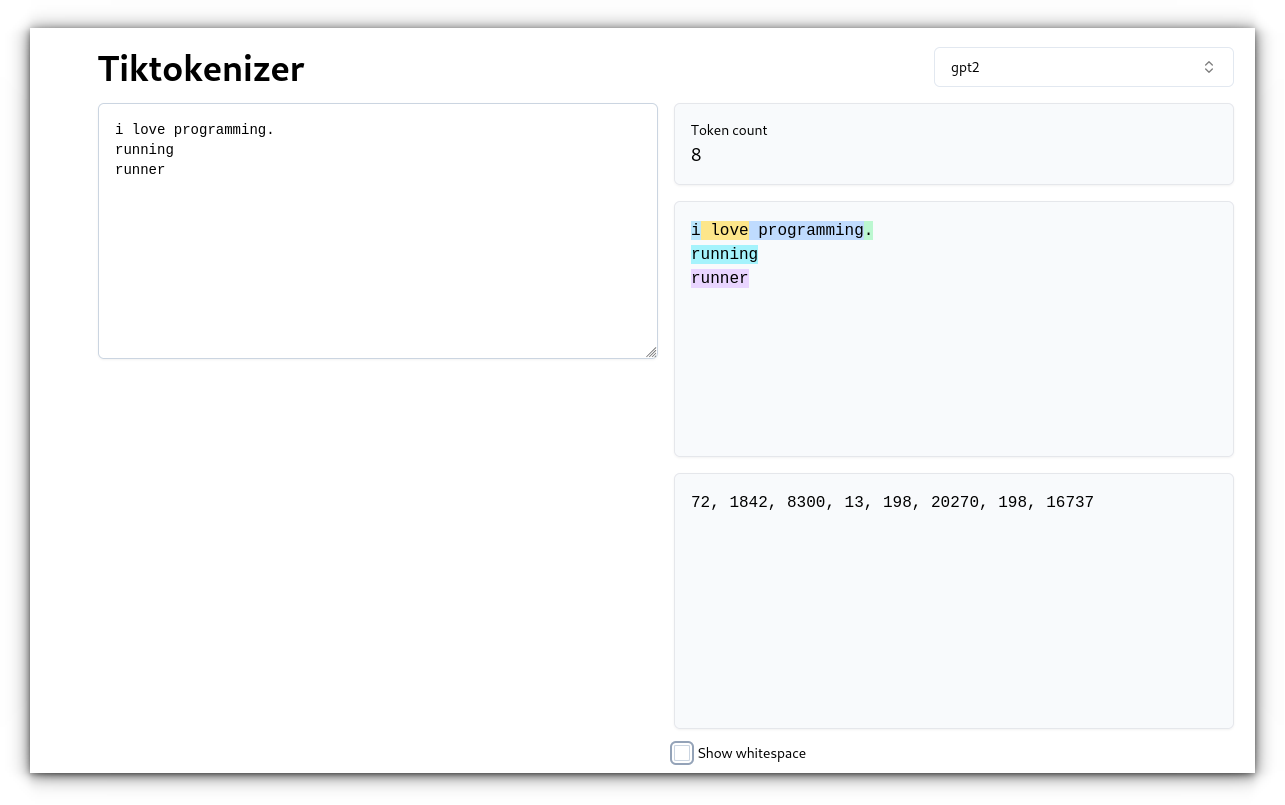
It’s great for handling words with common prefixes or suffixes and can split rare or misspelled words into known subwords. Subword tokenization breaks words into smaller, meaningful units, which makes it more efficient. When we talk about tokenization in the context of Large Language Models (LLMs), it’s important to understand that different methods are used to split text into tokens. Let’s walk through the most common approaches used today:Character-level tokenization is useful for extreme flexibility but often results in more tokens, which can be computationally heavier.4. Byte-Level TokenizationIt’s also important for cases where the exact representation of the text is crucial.While it may seem trivial at first, tokens influence everything from how efficiently a model processes language to its overall performance in different tasks and languages.Example: Original text: “I love programming.” Tokens: [“I”, “love”, “programming”, “.”]In this case, BPE breaks down “underestimate” into smaller units that can be used in other words, making it easier to handle variations and misspellings.Personally, I believe there’s room for improvement. LLMs still struggle with nuances in non-English languages or code, and tokenization plays a huge part in that.This method is especially useful for multilingual texts and languages that don’t use the Latin alphabet, like Chinese or Arabic.
Token Limit
A token in Large Language Models is basically a chunk of text that the model reads and understands. Once a text is tokenized, a language model can analyze each token to understand its meaning and context. This allows the model to:Imagine you’re trying to teach a child a new language. You’d start with the basics: letters, words, and simple sentences. Think of it as a buffer—there’s only so much data the model can hold and process at once. When you exceed this limit, the model will either stop processing or truncate the input.
Why Do Token Limits Matter?
- Contextual Understanding: LLMs rely on previous tokens to generate contextually accurate and coherent responses.
- If the model reaches its token limit, it loses the context beyond that point, which can result in less coherent or incomplete outputs.
- Input Truncation: If your input exceeds the token limit, the model will cut off part of the input, often starting from the beginning or end. This can lead to a loss of crucial information and affect the quality of the response.
- Output Limitation: If your input uses up most of the token limit, the model will have fewer tokens left to generate a response.
- For example, if you send a prompt that consumes 3900 tokens in GPT-3, the model only has 196 tokens left to provide a response, which might not be enough for more complex queries.
Conclusion
It’s one of those buzzwords that gets thrown around a lot, yet few people stop to explain it in a way that’s actually understandable. And here’s the catch – without a solid grasp of what tokens are, you’re missing a key piece of how these models function. Language models work in a similar way. They break down text into smaller, manageable units called tokens.So, let’s cut through the jargon and explore why tokens are so essential to how LLMs operate.