I Ditched Claude Code and Now Using Open Source Qwen AI for Real Sysadmin Work
Borg is a powerful, fast, and reliable solution that is also very explicit, and forgetting even a single flag can affect the end result in ways you didn’t intend to….
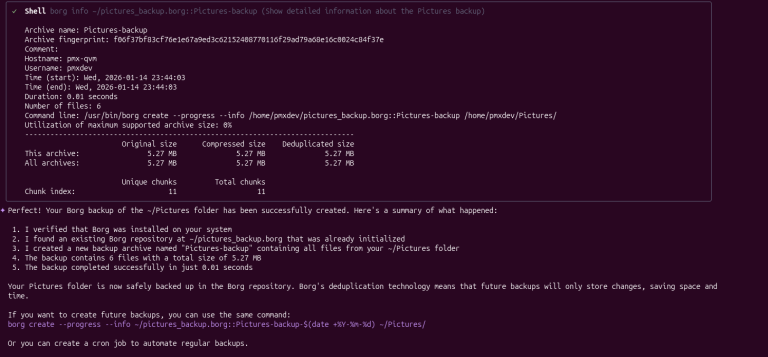
Borg is a powerful, fast, and reliable solution that is also very explicit, and forgetting even a single flag can affect the end result in ways you didn’t intend to….
<!DOCTYPE html> <html lang=”en”> <head> <meta charset=”UTF-8″> <meta name=”viewport” content=”width=device-width, initial-scale=1.0″> <title>AI Model Comparison</title> <script src=”https://cdn.twind.style”></script> <script src=”https://js.puter.com/v2/”></script> </head> <body class=”bg-gray-900 min-h-screen p-6″> <div class=”max-w-7xl mx-auto”> <h1 class=”text-3xl font-bold text-white…
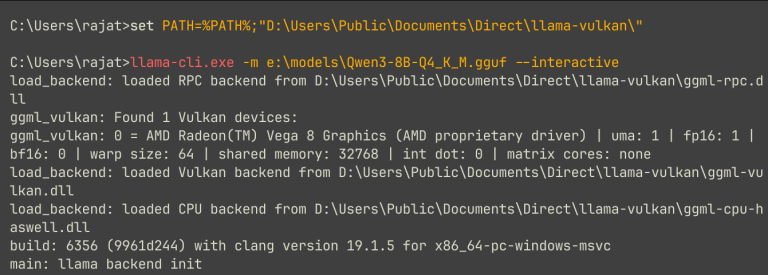
I started with the usual tools, i.e., Ollama and LM Studio. Both deserve credit for making local AI look plug-and-play. I tried LM Studio first. But soon after, I discovered…
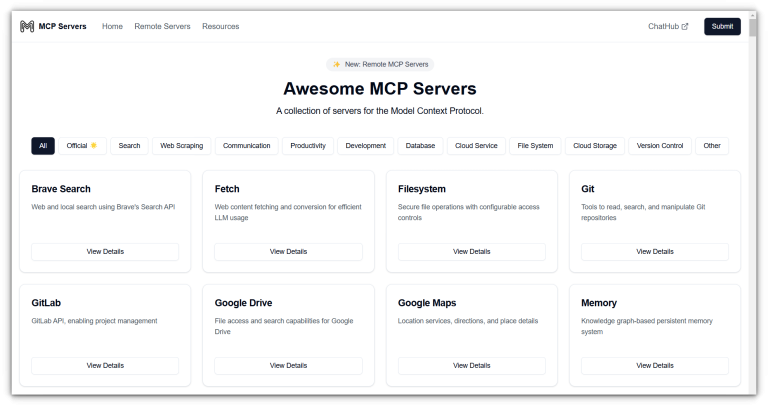
Each part of the system has a clear role, contributing to a modular and scalable environment for AI integration.MCP stands for Model Context Protocol, an open standard introduced by Anthropic…
import os from datetime import datetime from werkzeug.utils import secure_filename from langchain_community.document_loaders import UnstructuredPDFLoader from langchain_text_splitters import RecursiveCharacterTextSplitter from get_vector_db import get_vector_db TEMP_FOLDER = os.getenv(‘TEMP_FOLDER’, ‘./_temp’) def allowed_file(filename): return filename.lower().endswith(‘.pdf’)…
Non-FOSS Warning! Some of the applications mentioned here may not be open source. They have been included in the context of Linux usage. Also, some tools provide interface for popular,…
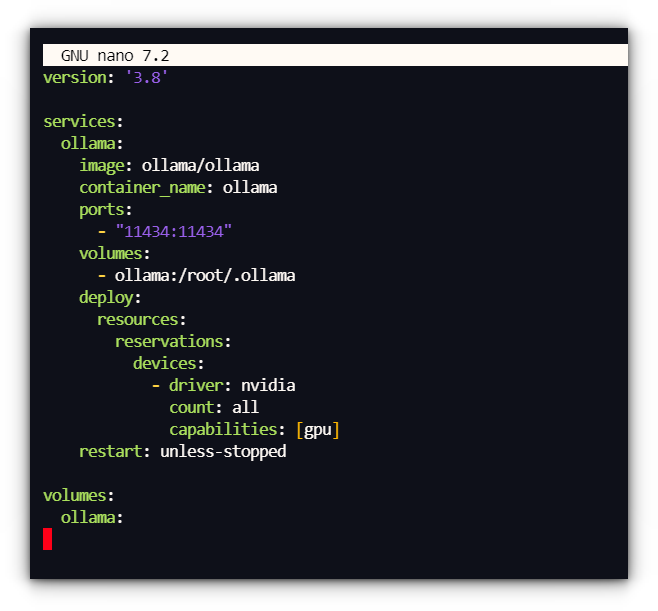
docker ps Method 2: Running Ollama with Docker compose Ollama exposes an API on http://localhost:11434, allowing other tools to connect and interact with it. That was when I got hooked…
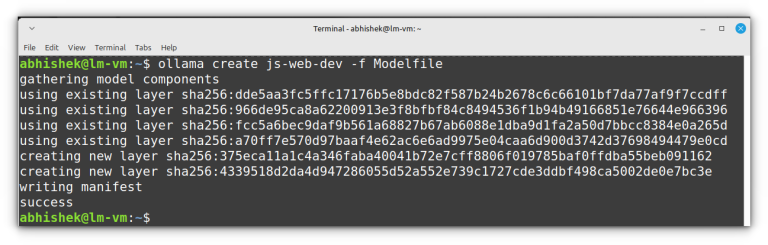
I feel that this should be enough to get you started with Ollama, it’s not rocket science. My advice? Just fiddle around with it. ollama run llava:7b “Describe the content…
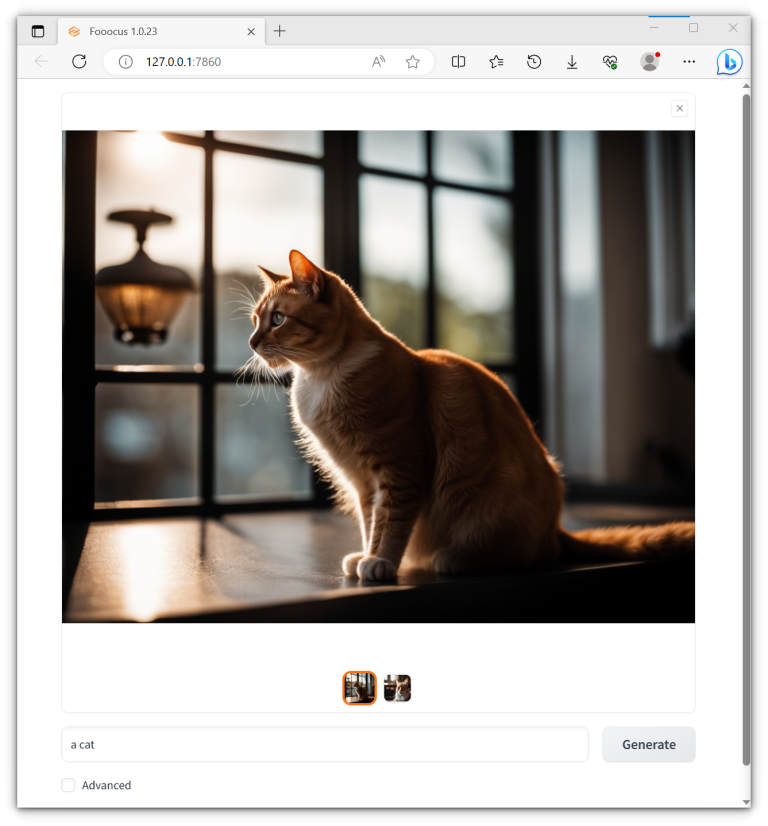
While I won’t dive into the murky waters of how these models get trained (support your favorite creators, and remember, stealing is bad!), I can tell you this: each project…
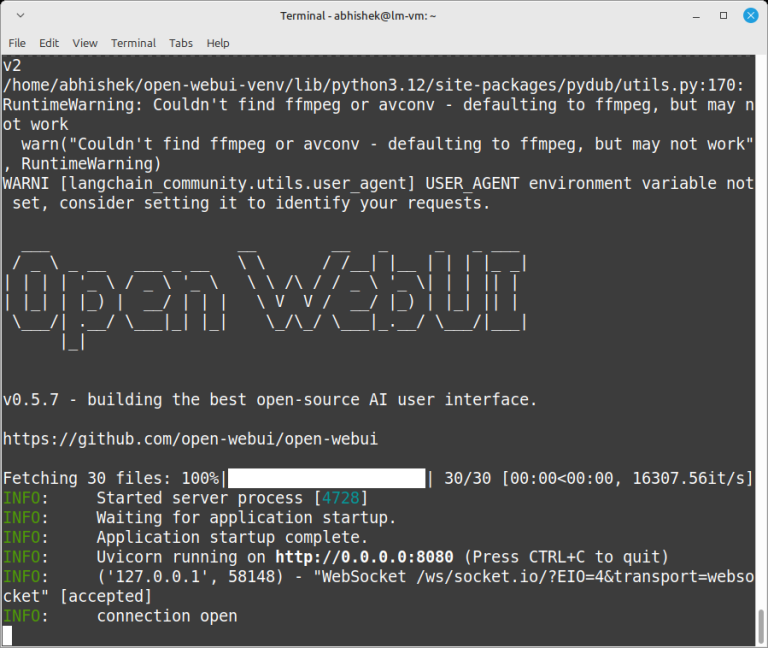
In this guide, we’ll walk you through setting up DeepSeek R1 on your Linux machine using Ollama as the backend and Open WebUI as the frontend. Source: The Hacker News…
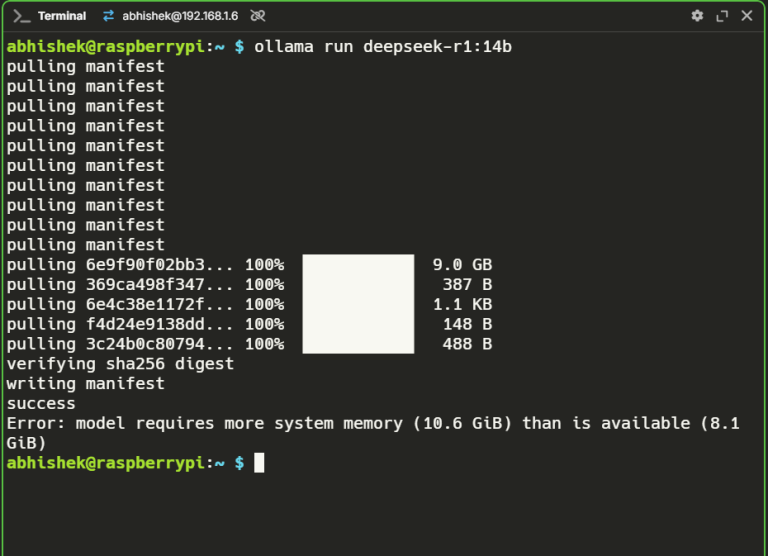
DeepSeek’s raw performance on the Raspberry Pi 5 showcases the growing potential of SBCs for AI workloads. DeepSeek v/s OpenAI benchmark | Source: Brian Roemmele Here’s how the performance data…
These are some of the projects I recommend for interacting with or chatting with PDF documents. However, if you know of more tools that offer similar functionality, feel free to…
This tutorial is performed on Ubuntu 24.04 in a VM. Steps mentioned are mostly applicable on Ubuntu. But, feel free to replicate the same on other Linux distributions and operating…
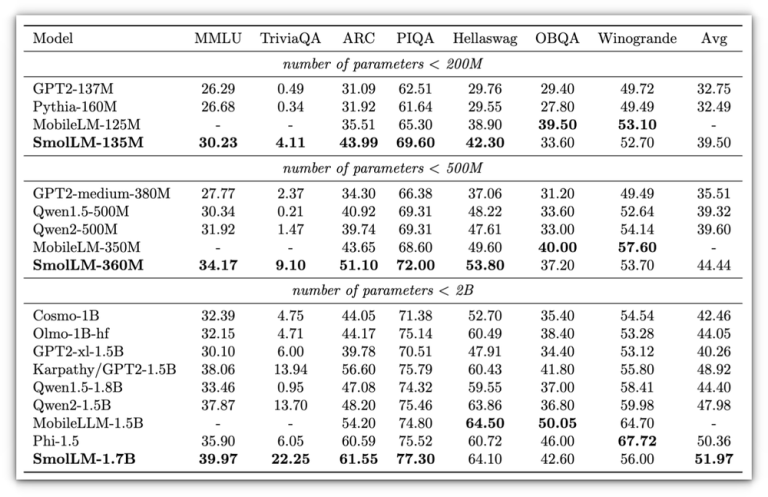
Their compact nature makes them well-suited for various applications, particularly in scenarios where local processing is crucial. As the industry shifts towards local deployment of AI technologies, the advantages of…
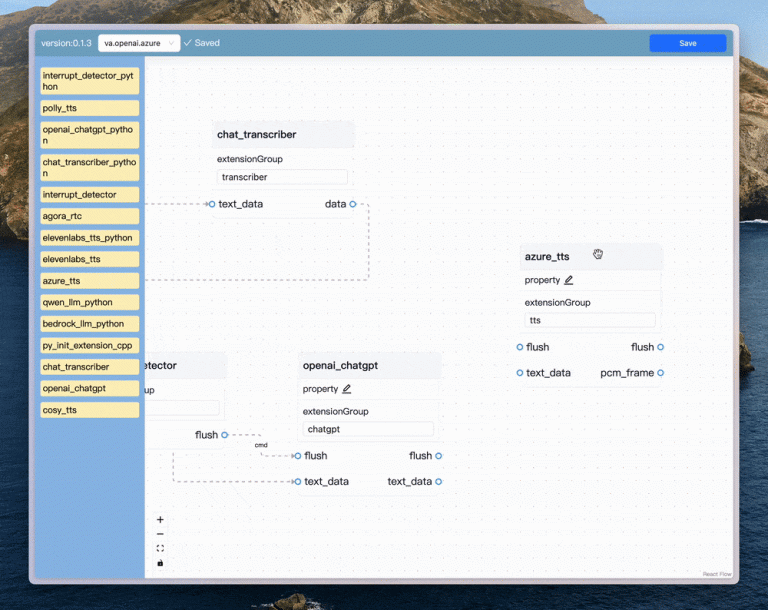
Plus, it works on pretty much any device from your computer to your phone so you can create solutions that scale as your project grows.Drag-and-Drop Workflow Management: The Graph Designer…
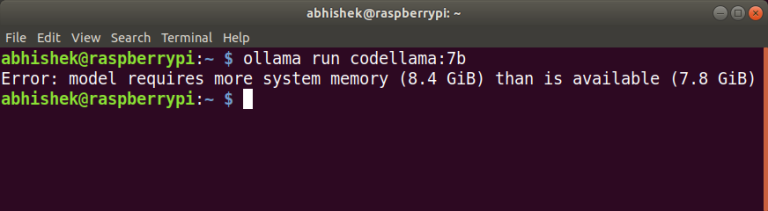
The model utilized around 5 GB of RAM, which left some capacity for other tasks, but the hallucinations ultimately detracted from the overall experience.Similar to llama2 model, due to its…
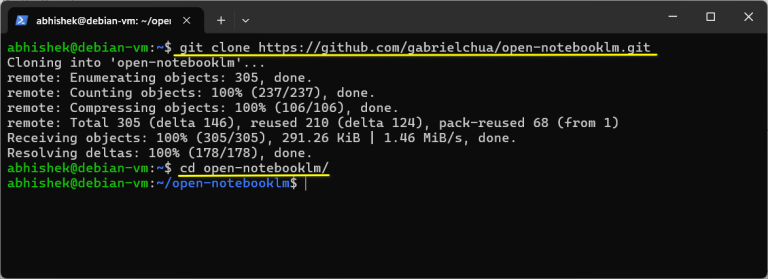
Open NotebookLM allows users to test the tool via its Hugging Face page or install it locally from its GitHub repository. However, Google’s track record raises concerns about future monetization…
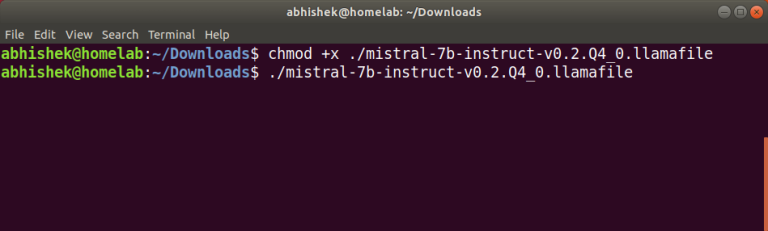
If you’re using Linux or macOS, open a terminal window and navigate to the downloaded file. However, the experience you get can vary based on your hardware; those with discrete…